
คุณถือว่าเป็นปัญหาส่วนบุคคลเมื่อใช้ Robots.txt
ทำความเข้าใจเกี่ยวกับความแตกต่างระหว่างไฟล์ robots.txt และ Robots & lt; META & gt; แท็กเป็นสิ่งสำคัญสำหรับการเพิ่มประสิทธิภาพกลไกค้นหาและความปลอดภัย อาจมีผลกระทบอย่างมากต่อความเป็นส่วนตัวของเว็บไซต์และลูกค้าของคุณด้วย สิ่งแรกที่ต้องทราบคือไฟล์ robots.txt และ Robots & lt; META & gt; แท็กคือ
Robots.txt
Robots.txt คือไฟล์ที่คุณวางไว้ในไดเรกทอรีระดับบนสุดของเว็บไซต์ซึ่งเป็นโฟลเดอร์เดียวกับที่หน้าแรกคงที่จะใช้งาน ภายใน robots.txt คุณสามารถสั่งให้เครื่องมือค้นหาไม่รวบรวมข้อมูลเนื้อหาโดยไม่อนุญาตให้ใช้ชื่อไฟล์หรือไดเรกทอรี มีสองส่วนของคำสั่ง robots.txt ผู้ใช้ user-agent และคำแนะนำที่ไม่ถูกต้องอย่างน้อยหนึ่งรายการ
user-agent ระบุโปรแกรมรวบรวมข้อมูลเว็บหรือแมงมานหนึ่งตัวหรือทั้งหมด เมื่อเรานึกถึงโปรแกรมรวบรวมข้อมูลเว็บเรามักคิดว่า Google และ Bing; อย่างไรก็ตามแมงมุมสามารถมาจากทุกแห่งไม่ใช่แค่เครื่องมือค้นหาเท่านั้นและมีหลายคนรวบรวมข้อมูลอินเทอร์เน็ต
นี่เป็นไฟล์ robots.txt แบบง่ายๆที่บอกโปรแกรมรวบรวมข้อมูลเว็บทั้งหมดว่าสามารถแมงมุมทุกหน้าได้:เพื่อไม่ให้เครื่องมือค้นหาทั้งหมดรวบรวมข้อมูลจากเว็บไซต์ทั้งหมดให้ใช้:
ความแตกต่างคือเครื่องหมายทับหลังจาก Disallow:
รับทำ SEO หมายถึงโฟลเดอร์รากและทุกอย่างในไฟล์รวมทั้งโฟลเดอร์ย่อยและไฟล์
Robots.txt มีหลากหลายรูปแบบ คุณไม่สามารถอนุญาตโฟลเดอร์ย่อยหรือไฟล์แต่ละไฟล์ได้ คุณสามารถไม่อนุญาตให้ใช้สไปเดอร์ของเครื่องมือค้นหาเฉพาะเช่น Googlebot และ Bingbot เครื่องมือค้นหาได้ขยาย robots.txt เพื่อรวมคำสั่ง อนุญาต
การจับคู่รูปแบบไฟล์หรือโฟลเดอร์และสถานที่ตั้งไซต์ XML
นี่คือไฟล์ robots.txt ที่สร้างขึ้นอย่างสวยงามจาก SEOmoz:
& nbsp;
หากคุณไม่คุ้นเคยกับ robots.txt อย่าลืมอ่านหน้าเว็บเหล่านี้:
http://support.google.com/webmasters/bin/answer.py?hl=en&answer=156449&from=40367&rd=1
http: // www.bing.com/webmaster/help/how-to-create-a-robots-txt-file-cb7c31ec
http://www.bing.com/community/site_blogs/b/webmaster /archive/2008/06/03/robots-exclusion-protocol-joining-together-to-provide-better-documentation.aspx
สิ่งที่ robots.txt ไม่ทำคือการเก็บไฟล์ออกจากดัชนีของเครื่องมือค้นหา สิ่งเดียวที่จะทำคือสั่งให้สไปเดอร์ของเครื่องมือค้นหาไม่รวบรวมข้อมูลหน้า โปรดจำไว้ว่าการค้นพบและการรวบรวมข้อมูลแยกจากกัน การค้นพบเกิดขึ้นเนื่องจากเครื่องมือค้นหาพบลิงก์ในเอกสาร เมื่อเครื่องมือค้นหาพบหน้าเว็บพวกเขาอาจหรือไม่อาจเพิ่มลงในดัชนีของพวกเขา
Robots.txt ไม่เก็บไฟล์จากดัชนีการค้นหา!
ดูตัวคุณเองได้ที่เว็บไซต์: permanent.access.gpo.gov
Robots.txt เป็นความเสี่ยงด้านความปลอดภัยหรือความเป็นส่วนตัวหรือไม่?การใช้ robots.txt เพื่อซ่อนไฟล์ที่ละเอียดอ่อนหรือเป็นส่วนตัวถือเป็นความเสี่ยงด้านความปลอดภัย ไม่เพียง แต่อาจค้นหาดัชนีเครื่องยนต์ไฟล์ที่ไม่ได้รับอนุญาตก็เหมือนกับการให้แผนที่สมบัติกับโจรสลัด ลองดูตัวคุณเองและดูว่าคุณเรียนรู้อะไรบ้าง
http://www.google.com/robots.txt
http://www.bing.com/robots.txt
http: / /searchengineland.com/robots.txt
นี่คือไฟล์ robots.txt ของ Search Engine Land
ฉันใช้เพื่อค้นหา inurl: http: //searchengineland.com/figz อย่างที่คุณเห็นฉันพบไฟล์บางไฟล์ที่ฉันอาจไม่ควรรู้
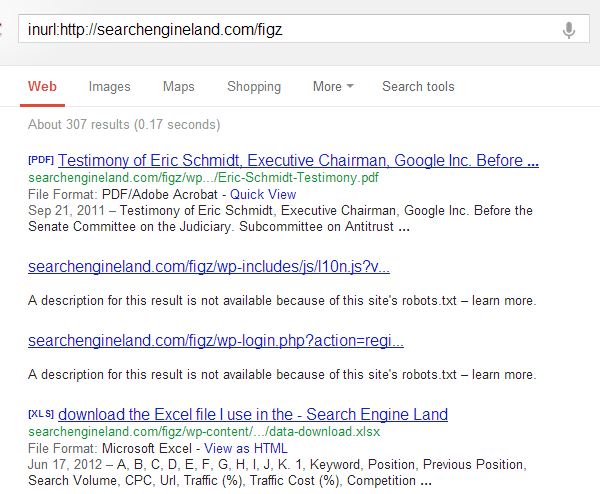 อย่ากังวล ถ้าฉันได้เห็นสิ่งที่มีความเสี่ยงหรือมีความละเอียดอ่อนใน Search Engine Land ฉันจะไม่มีวันแบ่งปันตัวอย่างนี้ คุณสามารถพูดเช่นเดียวกันเกี่ยวกับเว็บไซต์หรือใบสมัครออนไลน์ได้หรือไม่?ใช้หุ่นยนต์ & lt; META & gt; แท็กเพื่อเก็บไฟล์จากดัชนีการค้นหา
เนื่องจาก robots.txt ไม่ได้ยกเว้นไฟล์จากดัชนีการค้นหา Google และ Bing จะทำตามโปรโตคอลที่ทำอย่างนั้นซึ่ง Robots & lt; META & gt; แท็ก
หุ่นยนต์ & lt; META & gt; ให้คำแนะนำสองแบบ:
ดัชนีหรือ noindex แนะนำเครื่องมือค้นหาว่าจะทำดัชนีหน้าเว็บหรือไม่ เมื่อคุณเลือกดัชนีพวกเขาอาจหรือไม่อาจเลือกที่จะรวมเว็บเพจไว้ในดัชนี หากเลือก noindex เครื่องมือค้นหาจะไม่รวมชื่อดังกล่าว
ปฏิบัติตามหรือ nofollow สั่งให้โปรแกรมรวบรวมข้อมูลเว็บไม่ว่าจะติดตามลิงก์บนหน้าเว็บหรือไม่ก็ตาม เหมือนกับการเพิ่มแท็ก rel = "nofollow" ลงในลิงก์ทุกหน้า Nofollow ระเหย PageRan
k หน่วยงานด้านการจัดอันดับของเครื่องมือค้นหาดิบถูกส่งผ่านจากหน้าเว็บไปยังอีกกลุ่มหนึ่งผ่านลิงก์ แม้ว่าคุณจะพิมพ์หน้าเว็บหนึ่งหน้าอาจเป็นความคิดที่ไม่ดีในการ nofollow ก็ตาม ให้ PageRank ไหลผ่านข้อสรุปขั้นสุดท้าย มิฉะนั้นคุณอาจจะเทน้ำผลไม้ที่ดีอย่างสมบูรณ์ลงท่อระบายน้ำ
เมื่อคุณต้องการยกเว้นหน้าจากดัชนีของเครื่องมือค้นหาให้ทำดังนี้
ไม่มีการหยุดพฤติกรรมแย่ ๆ
ปัญหาที่คุณจะพบกับ robots.txt และ robots & lt; META & gt; คือคำแนะนำเหล่านี้ไม่สามารถบังคับใช้คำสั่งของตนได้ แม้ว่า Google และ Bing จะเคารพคำแนะนำของคุณอย่างแน่นอน แต่ผู้ที่ใช้กบกรีดร้อง Xenu หรือโปรแกรมรวบรวมข้อมูลไซต์ที่กำหนดเองของพวกเขาก็สามารถละเว้นคำสั่ง disallow และ noindex ได้
การรักษาความปลอดภัยเพียงอย่างเดียวคือการล็อคเนื้อหาส่วนตัวหลังการเข้าสู่ระบบ หากธุรกิจของคุณอยู่ในพื้นที่ที่แข่งขันคุณจะได้รับการรวบรวมข้อมูลเป็นครั้งคราวและมีบางสิ่งที่คุณสามารถทำได้เพื่อหยุดหรือขัดขวางธุรกิจของคุณ
หนึ่งข้อความล่าสุดฉันไม่ปล่อยให้แมวใด ๆ ออกจากกระเป๋าที่นี่ โจรสลัดและแฮกเกอร์รู้เรื่องนี้ทั้งหมด พวกเขารู้จักมานานหลายปีแล้ว ตอนนี้คุณทำเช่นกัน
ความคิดเห็นบางอย่างที่แสดงในบทความนี้อาจเป็นของผู้เขียนทั่วไปและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนมีรายชื่ออยู่ที่นี่
เกี่ยวกับผู้แต่ง
เรื่องราวยอดนิยมหัวข้อที่เกี่ยวข้อง
อย่ากังวล ถ้าฉันได้เห็นสิ่งที่มีความเสี่ยงหรือมีความละเอียดอ่อนใน Search Engine Land ฉันจะไม่มีวันแบ่งปันตัวอย่างนี้ คุณสามารถพูดเช่นเดียวกันเกี่ยวกับเว็บไซต์หรือใบสมัครออนไลน์ได้หรือไม่?ใช้หุ่นยนต์ & lt; META & gt; แท็กเพื่อเก็บไฟล์จากดัชนีการค้นหา
เนื่องจาก robots.txt ไม่ได้ยกเว้นไฟล์จากดัชนีการค้นหา Google และ Bing จะทำตามโปรโตคอลที่ทำอย่างนั้นซึ่ง Robots & lt; META & gt; แท็ก
หุ่นยนต์ & lt; META & gt; ให้คำแนะนำสองแบบ:
ดัชนีหรือ noindex แนะนำเครื่องมือค้นหาว่าจะทำดัชนีหน้าเว็บหรือไม่ เมื่อคุณเลือกดัชนีพวกเขาอาจหรือไม่อาจเลือกที่จะรวมเว็บเพจไว้ในดัชนี หากเลือก noindex เครื่องมือค้นหาจะไม่รวมชื่อดังกล่าว
ปฏิบัติตามหรือ nofollow สั่งให้โปรแกรมรวบรวมข้อมูลเว็บไม่ว่าจะติดตามลิงก์บนหน้าเว็บหรือไม่ก็ตาม เหมือนกับการเพิ่มแท็ก rel = "nofollow" ลงในลิงก์ทุกหน้า Nofollow ระเหย PageRan
k หน่วยงานด้านการจัดอันดับของเครื่องมือค้นหาดิบถูกส่งผ่านจากหน้าเว็บไปยังอีกกลุ่มหนึ่งผ่านลิงก์ แม้ว่าคุณจะพิมพ์หน้าเว็บหนึ่งหน้าอาจเป็นความคิดที่ไม่ดีในการ nofollow ก็ตาม ให้ PageRank ไหลผ่านข้อสรุปขั้นสุดท้าย มิฉะนั้นคุณอาจจะเทน้ำผลไม้ที่ดีอย่างสมบูรณ์ลงท่อระบายน้ำ
เมื่อคุณต้องการยกเว้นหน้าจากดัชนีของเครื่องมือค้นหาให้ทำดังนี้
ไม่มีการหยุดพฤติกรรมแย่ ๆ
ปัญหาที่คุณจะพบกับ robots.txt และ robots & lt; META & gt; คือคำแนะนำเหล่านี้ไม่สามารถบังคับใช้คำสั่งของตนได้ แม้ว่า Google และ Bing จะเคารพคำแนะนำของคุณอย่างแน่นอน แต่ผู้ที่ใช้กบกรีดร้อง Xenu หรือโปรแกรมรวบรวมข้อมูลไซต์ที่กำหนดเองของพวกเขาก็สามารถละเว้นคำสั่ง disallow และ noindex ได้
การรักษาความปลอดภัยเพียงอย่างเดียวคือการล็อคเนื้อหาส่วนตัวหลังการเข้าสู่ระบบ หากธุรกิจของคุณอยู่ในพื้นที่ที่แข่งขันคุณจะได้รับการรวบรวมข้อมูลเป็นครั้งคราวและมีบางสิ่งที่คุณสามารถทำได้เพื่อหยุดหรือขัดขวางธุรกิจของคุณ
หนึ่งข้อความล่าสุดฉันไม่ปล่อยให้แมวใด ๆ ออกจากกระเป๋าที่นี่ โจรสลัดและแฮกเกอร์รู้เรื่องนี้ทั้งหมด พวกเขารู้จักมานานหลายปีแล้ว ตอนนี้คุณทำเช่นกัน
ความคิดเห็นบางอย่างที่แสดงในบทความนี้อาจเป็นของผู้เขียนทั่วไปและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนมีรายชื่ออยู่ที่นี่
เกี่ยวกับผู้แต่ง
เรื่องราวยอดนิยมหัวข้อที่เกี่ยวข้อง
อย่ากังวล ถ้าฉันได้เห็นสิ่งที่มีความเสี่ยงหรือมีความละเอียดอ่อนใน Search Engine Land ฉันจะไม่มีวันแบ่งปันตัวอย่างนี้ คุณสามารถพูดเช่นเดียวกันเกี่ยวกับเว็บไซต์หรือใบสมัครออนไลน์ได้หรือไม่?ใช้หุ่นยนต์ & lt; META & gt; แท็กเพื่อเก็บไฟล์จากดัชนีการค้นหา
เนื่องจาก robots.txt ไม่ได้ยกเว้นไฟล์จากดัชนีการค้นหา Google และ Bing จะทำตามโปรโตคอลที่ทำอย่างนั้นซึ่ง Robots & lt; META & gt; แท็ก
หุ่นยนต์ & lt; META & gt; ให้คำแนะนำสองแบบ:
ดัชนีหรือ noindex แนะนำเครื่องมือค้นหาว่าจะทำดัชนีหน้าเว็บหรือไม่ เมื่อคุณเลือกดัชนีพวกเขาอาจหรือไม่อาจเลือกที่จะรวมเว็บเพจไว้ในดัชนี หากเลือก noindex เครื่องมือค้นหาจะไม่รวมชื่อดังกล่าว
ปฏิบัติตามหรือ nofollow สั่งให้โปรแกรมรวบรวมข้อมูลเว็บไม่ว่าจะติดตามลิงก์บนหน้าเว็บหรือไม่ก็ตาม เหมือนกับการเพิ่มแท็ก rel = "nofollow" ลงในลิงก์ทุกหน้า Nofollow ระเหย PageRan
k หน่วยงานด้านการจัดอันดับของเครื่องมือค้นหาดิบถูกส่งผ่านจากหน้าเว็บไปยังอีกกลุ่มหนึ่งผ่านลิงก์ แม้ว่าคุณจะพิมพ์หน้าเว็บหนึ่งหน้าอาจเป็นความคิดที่ไม่ดีในการ nofollow ก็ตาม ให้ PageRank ไหลผ่านข้อสรุปขั้นสุดท้าย มิฉะนั้นคุณอาจจะเทน้ำผลไม้ที่ดีอย่างสมบูรณ์ลงท่อระบายน้ำ
เมื่อคุณต้องการยกเว้นหน้าจากดัชนีของเครื่องมือค้นหาให้ทำดังนี้
ไม่มีการหยุดพฤติกรรมแย่ ๆ
ปัญหาที่คุณจะพบกับ robots.txt และ robots & lt; META & gt; คือคำแนะนำเหล่านี้ไม่สามารถบังคับใช้คำสั่งของตนได้ แม้ว่า Google และ Bing จะเคารพคำแนะนำของคุณอย่างแน่นอน แต่ผู้ที่ใช้กบกรีดร้อง Xenu หรือโปรแกรมรวบรวมข้อมูลไซต์ที่กำหนดเองของพวกเขาก็สามารถละเว้นคำสั่ง disallow และ noindex ได้
การรักษาความปลอดภัยเพียงอย่างเดียวคือการล็อคเนื้อหาส่วนตัวหลังการเข้าสู่ระบบ หากธุรกิจของคุณอยู่ในพื้นที่ที่แข่งขันคุณจะได้รับการรวบรวมข้อมูลเป็นครั้งคราวและมีบางสิ่งที่คุณสามารถทำได้เพื่อหยุดหรือขัดขวางธุรกิจของคุณ
หนึ่งข้อความล่าสุดฉันไม่ปล่อยให้แมวใด ๆ ออกจากกระเป๋าที่นี่ โจรสลัดและแฮกเกอร์รู้เรื่องนี้ทั้งหมด พวกเขารู้จักมานานหลายปีแล้ว ตอนนี้คุณทำเช่นกัน
ความคิดเห็นบางอย่างที่แสดงในบทความนี้อาจเป็นของผู้เขียนทั่วไปและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนมีรายชื่ออยู่ที่นี่
เกี่ยวกับผู้แต่ง
เรื่องราวยอดนิยมหัวข้อที่เกี่ยวข้อง แสดงความคิดเห็นที่ 0-0 จากทั้งหมด 0 ความคิดเห็น

MEMBER
 ร้านดอกไม้ขอนแก่นฟลาวเวอร์คาเฟ่ Flower Cafe Flowers Delivery Khonkaen
ร้านดอกไม้ขอนแก่นฟลาวเวอร์คาเฟ่ Flower Cafe Flowers Delivery Khonkaen
สมัครสมาชิกร้านนี้ เพื่อรับสิทธิพิเศษ
 ธ.กสิกรไทย
ธ.กสิกรไทย
สินค้าในตะกร้า ({{total_num}} รายการ)

ขออภัย ขณะนี้ยังไม่มีสินค้าในตะกร้า
ราคาสินค้าทั้งหมด
฿ {{price_format(total_price)}}
- ฿ {{price_format(discount.price)}}
ราคาสินค้าทั้งหมด
{{total_quantity}} ชิ้น
฿ {{price_format(after_product_price)}}
ราคาไม่รวมค่าจัดส่ง
➜ เลือกซื้อสินค้าเพิ่ม